


2026 年做新站,最麻烦的安全问题之一就是劫持,而且它早就不是“跳错页面”这么简单了。新站没有历史信誉,规则也没调稳,最容易被盯上。攻击者常见的做法包括篡改 DNS、做中间人攻击、污染本地缓存,把访问者悄悄带到恶意页面,再去偷数据、塞广告,或者下发恶意脚本。
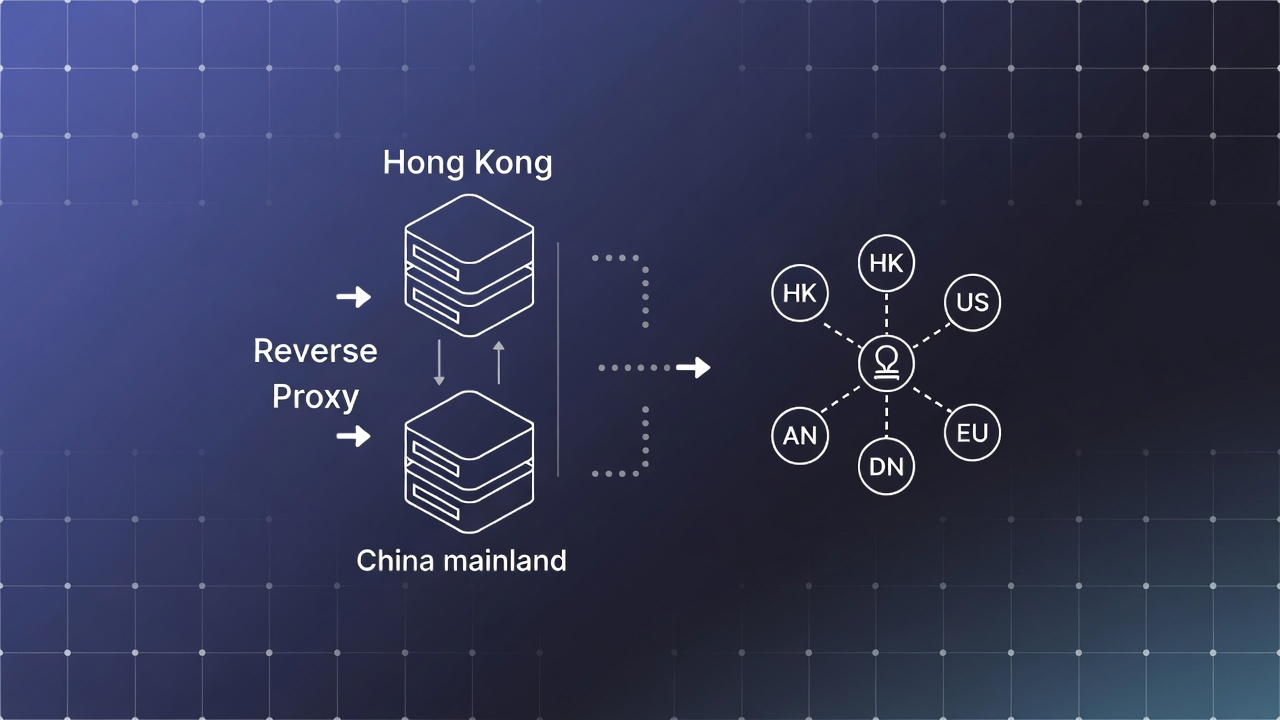
只靠传统防火墙,或者只给站点上 HTTPS,通常不够。更实际的做法,是把防线分成两层:前面用 Nginx 识别和拦截异常流量,后面再用 AI 做页面内容校验。前者盯请求,后者盯结果。这样即使有攻击绕过入口,也不至于直接把被篡改的内容送到用户面前。
先看 Nginx 这一层。它本来就是常见的反向代理,扛并发没什么问题,配置也灵活。在防劫持场景里,Nginx 不只是转发流量,更像站点门口的筛子。可以通过 Lua 脚本或第三方模块,对请求做实时判断:看来源 IP、请求频率、请求头、访问路径、UA 是否异常,必要时结合 IP 信誉库一起判断。
比如一个 IP 在很短时间内连续打大量探测请求,或者请求头明显不像正常浏览器,这种流量就可以先限速、丢进验证流程,严重的直接拒绝。这里不需要把逻辑写得太花,先把最常见的扫描、批量探测、伪造请求头挡掉,已经能减轻后端不少压力。
落地时,Nginx 配置通常从几件事开始做。第一,限制请求频率和并发连接数,避免站点刚上线就被扫垮。第二,检查 Host、Referer、User-Agent 这些基础字段,过滤明显不对劲的请求。第三,接入黑名单或信誉库,把已知恶意 IP 先挡在外面。第四,把异常访问单独记日志,别和普通访问日志混在一起,不然后面排查会很痛苦。
如果还想再往前走一步,可以把机器学习模型接进这层流程里,不过别一上来就想得太重。更稳妥的办法,是先用历史日志训练一个异常访问识别模型,给请求打风险分。分高的请求,不一定立刻封掉,可以先要求验证码、二次校验,或者返回挑战页。这样误伤会少一些,也更适合新站前期慢慢调规则。
Nginx 这一层解决的是“谁在访问、访问像不像正常人”的问题。可真正麻烦的是,有些攻击流量看起来很正常,最后却把页面内容动了手脚。这时候就得靠第二层,也就是 AI 内容校验。
这一层的思路很直接:页面在输出给用户之前,再检查一遍内容是不是对的。传统规则更擅长抓已知特征,比如固定的恶意脚本片段、特定注入模式。但遇到改得很细、藏得很深的篡改,单靠规则经常抓不住。AI 的价值就在这里。它不只是比对几行字符串,而是看页面整体结构有没有异常,脚本、资源链接、DOM 变化是不是可疑,必要时还可以结合截图做视觉比对。
举个很典型的例子:攻击者往页面底部塞一段隐藏的 JavaScript,或者把一张正常图片偷偷换成带跳转的资源。源码改动可能很小,人工巡检未必能立刻看出来,但如果模型已经学过正常页面的结构和资源关系,这种变化往往会被标出来。
实际部署时,AI 校验最好做成独立服务,不要硬塞进主应用里。主站负责生成页面,校验服务通过 API 接收 HTML、脚本、资源清单,必要时还可以拿到渲染后的截图。它分析完后,返回一个结果:正常、可疑,还是高风险。高风险就拦截,可疑就记日志加告警,正常再放行。
为了不把延迟拉得太高,可以分场景处理。核心页面,比如登录、注册、支付、后台入口,做实时校验。更新不频繁的静态页面,可以提前校验并缓存结果。访问量大但风险低的页面,做抽样或异步复检也行。安全当然重要,但用户一打开页面要等两秒才显示,最后还是会把自己拖死。
模型本身也别想成万能解药。它需要定期更新,训练数据得覆盖正常页面、已知篡改样本、误报案例,不然要么太敏感,到处报警;要么太迟钝,真出事了还看不出来。很多团队前期踩的坑,不是模型不高级,而是样本太脏、标注太乱,最后输出一堆没法用的结果。
这套双层防御上了之后,日志和监控必须跟上。Nginx 拦了什么、为什么拦,AI 判了什么、误报率多少,都要看得见。用 ELK 之类的日志方案做集中分析是比较常见的路子,至少能把异常请求、拦截记录、模型结果、后端响应串起来。否则出了问题,你只会知道“页面不对了”,却不知道是入口漏了,还是内容层没抓住。
监控项也别做得太虚。重点看几类:异常请求量有没有突然飙升,某类页面的校验失败率有没有集中上涨,验证码或挑战页的触发率是不是异常,模型误报有没有突然变高,Nginx 和 AI 服务的 CPU、内存、响应时间是不是开始顶不住。数据一旦连起来,很多问题其实会自己冒出来。
新站上线初期,误拦正常用户几乎是躲不开的事。规则太松,拦不住;规则太紧,正常流量也进不来。所以别指望第一版就完美,应该留出一段观察期。可以先对一部分流量启用严格策略,看误报情况,再逐步放大范围。A/B 测试、防御规则灰度发布,这些办法在安全场景里一样有用,而且很实在。
技术选型上,Nginx 继续做入口没什么争议,成熟、稳定,生态也够全。AI 校验服务如果团队有算法能力,可以用 TensorFlow 或 PyTorch 自己训模型;如果没有,就先从规则加轻量模型开始,别一上来就堆复杂架构。很多时候,能稳定识别 80% 的常见篡改,比追求一个听起来很厉害但维护不了的系统更有价值。
部署上,用容器化拆开 Nginx、业务服务和 AI 校验服务,会省事很多。再往上交给 Kubernetes 管理,扩容、回滚、健康检查都方便,单点故障也好处理。不过这套东西一多,配置和文档就不能乱。Nginx 配置最好按功能拆分,限流、黑名单、转发、告警分别放;模型版本、规则变更、回滚流程也要写清楚。安全系统最怕的不是功能少,而是出问题时没人说得清它现在到底在跑什么。
说到底,这套方案真正有用的地方,不是某个单点技术多“智能”,而是它把入口流量和页面结果都看住了。Nginx 负责把大多数粗糙攻击挡在外面,AI 内容校验负责盯住那些已经钻进来的细小篡改。两层配合,比单独堆一个 WAF 或单独做内容巡检靠谱得多。
当然,它也不是终点。攻击手法一直在变,今天有效的规则,明天可能就被绕过去;今天训练好的模型,过一阵子也可能开始漂移。所以这套体系要一直调,一直看数据,一直更新。新站安全从来不是“部署完成”四个字,而是上线后每天都要维护的东西。真要说经验,我更愿意把它理解成一套持续运转的工程,而不是一次性的项目。只要这点想明白,后面的取舍就会现实很多。


评论一下?